
It was a pleasure to have Adam Tornhill at Codecamp_Festival this spring! Adam is a programmer who combines degrees in engineering and psychology. He’s the founder & CTO of CodeScene where he designs tools for building great software. He’s also the author of Software Design X-Rays, the best-selling Your Code as a Crime Scene, Lisp for the Web and Patterns in C.
At Codecamp_Festival, Adam talked about the business impact of code quality, and here is a glimpse of his talk: Code Red: the business impact of code quality
Somewhere between 23-42% of a developer’s time is wasted dealing with the consequences of technical debt or bad code in general. What that means to me, as a business manager, is that if I have 100 developers in my organization, 42 are non-productive. I’m getting the equivalent output of just 58 people. And in reality, the waste is even larger, and to understand this better, we need to talk about teamwork. Most software developers are part of teams and have been part of a team-building exercise. We have all done this. We all know the benefits of team building, we know the benefits of being on a team.
I am going to talk about something different, more like an anti-team building exercise, because like all great things, there’s also a trade-off. Nothing is ever free, and it’s the same for teamwork. It always comes with a cost and that cost is something that social psychologists refer to as process loss.
Process loss is a term that social psychologists have stolen from the field of mechanics. The idea behind it is that just like a machine cannot operate at 100% efficiency all the time due to things like friction and heat loss, neither can a team. Let’s say, we have a number of individuals together, and they have a certain potential productivity. However, the actual productivity we get is always smaller and part of the potential is simply lost.
The type of loss depends on the task that we do but for complex interdependent tasks, like software development, a big part of that process loss is simply due to coordination and communication overhead. And what that means in the context of technical debt is that you waste 42% of developers’ time and we can never make up for that. We can never compensate for that by hiring even more people, because the process loss increases non-linearly, so at some point, each individual that we add is actually going to cost us more. The more we can do with a smaller team, the better we are.
So, we simply need to start managing technical depth. Given what I explained about process loss and given the fact that there’s a global shortage of software developers, does it make sense that we waste 42% of developers’ time?
You would expect technical debt to be really high on any decision-maker’s agenda, which of course, it never is in reality, because the research constantly finds that many businesses keep forcing developers to take new technical depth, as they hunt for the next feature that they need to deliver.
So, why is this happening? Why aren’t we doing a better job at managing technical debt?
I think I know why, and I would like to explain why that happens. We need to look at some laws of software evolution and at what happens when we build code.
The first law of software evolution is the law of continuing change, and the law of continuous change simply says that the system has to continuously evolve and adapt or it will become progressively less useful over time. This is the very reason why we keep getting new features to existing products. Because a successful product is never done.
What needs to be noticed is that there is some tension, some conflict, to the second law of software evolution and that’s the law of increasing complexity. And this law says that when we evolve our systems, their complexity will increase unless we actively try to reduce it.
So that’s what’s happening when we take on technical depth. The complexity increases, which in turn, makes it harder and harder to respond to change. If we take an outside perspective and look at these two laws together, we will see that there’s a difference in feedback timing. When we release a new feature, we get very quick and immediate feedback, the moment we put it in the hands of a user. Whereas, for increasing complexity, the feedback timing is much longer. This is something that happens over time and this difference in feedback timing is like an open invitation to something that psychologists know as a decision-making bias of hyperbolic discounting.
Hyperbolic discounting is a decision-making bias where our current self makes decisions that our future self is going to regret. Hyperbolic discounting is frequently used in the psychology of addiction to explain substance abuse and addiction. It’s also, coincidentally, the best description of why companies fail to manage technical debt. Because companies, just like the addict, are lured in by the promise of the next quick fix, the next immediate reward. Delivering and pushing those features that seem urgent out, is done at the expense of long-term well-being, which in terms of software, means a maintainable and sustainable code base.
To fight hyperbolic discounting it’s really important to visualize the potential consequences because if we can visualize them, we can convince decision-makers to start thinking about the future, which makes it much more likely that they will actually act now.
How can we visualize accidental code complexity and technical debt? Software kind of lacks visibility. When talking about complicated code, we have to understand that it’s really hard to measure the complexity. If we look for a single number, a single metric to capture a multifaceted concept like code quality or code complexity, then we are doomed. Software is just way too complicated.
The most promising approach is to identify specific attributes of complexity and measure them separately. I’ve been calling this concept code health. We define properties, that we know from research, that lead to increased maintenance costs. In the current code health concept, I have 25 different factors to measure. We measure them separately, we aggregate them, we normalize them and we can then categorize every single piece of code in a system as being in one of three different categories:
Green code – perfectly healthy code, no code smells, no particular complexion issues;
Yellow code – Increased maintenance code, this is where we have technical depth
Red code – here is where we have high maintenance code, that is disastrous to business
To give you an idea of what we measure in a code of concept, we look at typical module levels, things like:
low cohesion – when you have a module and it includes way too many responsibilities. We have put too many features into that module and that in turn, makes the code very hard to understand and it also puts you at risk for things like unexpected feature interaction;
brain classes – a module with low cohesion that also contains a brain method.
On the function levels, we look at:
brain methods – typically very large functions that are overly complicated, that have lots of conditional logic and that tend to be very central to the module, meaning that each time you go into the code to make a change to that module, you end up in the brain method and they typically grow more complicated over time
copy-pasted logic
On the implementation levels, we have:
deeply nested logic – when you have an if statement, then you have another if statement, deciding another if statement and then, maybe a for loop for good measure, so your code looks kind of like an arrow. The reason why this is problematic is that it puts a huge load on our cognitive memory
primitive obsession – missing a domain language
Next, we need to understand if the code health categories actually mean something from a business perspective, because without the business connection, all of these are just vanity metrics.
So, we tried to quantify the business impact of complex code. We collected data from 39 commercial code bases, real-world code bases under active development at 39 different companies, data analytics, infrastructure, networking, and all kinds of domains because we wanted to make sure that whatever we find, we would be able to generalize across businesses.
And for the same reason, we included code in 14 different program languages, to make sure that our findings weren’t specific to a certain language.
What we decided to do, was to measure the time in development: does it take longer to develop a feature in red code versus green code? The main problem with that is that no organization actually knows its development costs. They don’t know how much time they spend on development. And this sounds like a really strange statement. As managers, we know what our staffing costs are: we know we have 10 developers, and the salaries we pay them.
With some Jira magic, we could figure out roughly how those costs are distributed across different Jira tickets, so I could kind of calculate that we spent these many hours on this particular feature. Previously, we had no way of knowing how those costs are distributed across potentially thousands of modules in a code base of various qualities. We never had that level of detail. So this was the first challenge that we needed to attack, and we did that by using the following algorithm:
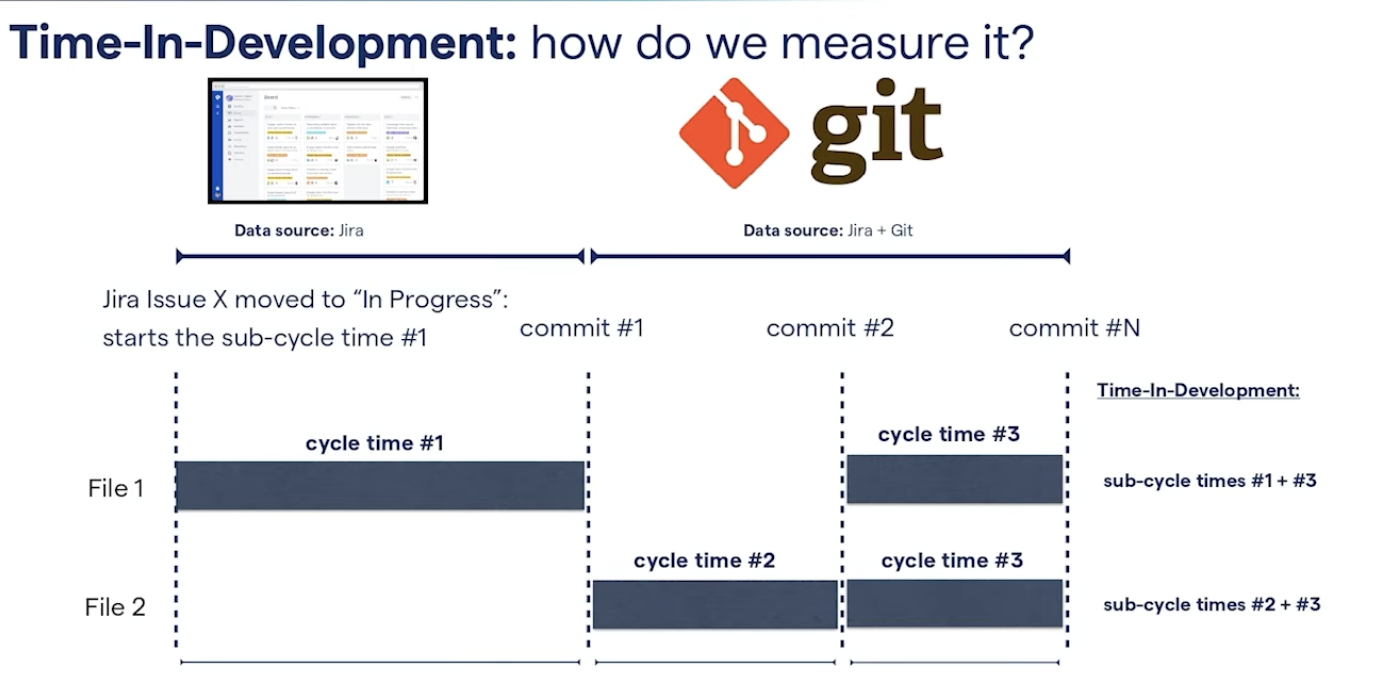
We pieced together data from Jira and Git, so, for every single feature, every single Jira card, we start the clock for time and development the moment we, as a developer, pull a card to an in-progress state. When we make a commitment, we pause the clock. If the feature is done at this stage, then the cycle time between ticket movement in progress until the first commit is the time and development for that Jira card.
But sometimes, we do multiple commits and if that happens, then we calculate the cycle time from the previous commit to the next commit. And we might even do a third commit. In the end, we simply sum up these different subcycle times so we get a total time and development per file per Jira.
Now, we had a data set that included the code health for every single file, the time and development for every single file and since we’re using Jira, we could also figure out how many bugs fixes we have done in each one of the files so we can finally answer the question: does code quality matter?
And this is a question I wanted to answer for decades, because I’ve spent 25 years in the software industry, and during those 25 years I have more or less learned that everyone knows that code quality is important yet no one ever had any data to support that statement.
The average time in development, depending on code quality can vary immensely. If I implement a feature or fix a bug in red code then that takes more than twice as long as making a change to green code. To a decision maker, what this means is that if it took my team two and a half weeks to implement a specific feature, and our code is red, then our competitors, that have a green code base, could get the same feature in less than one week.
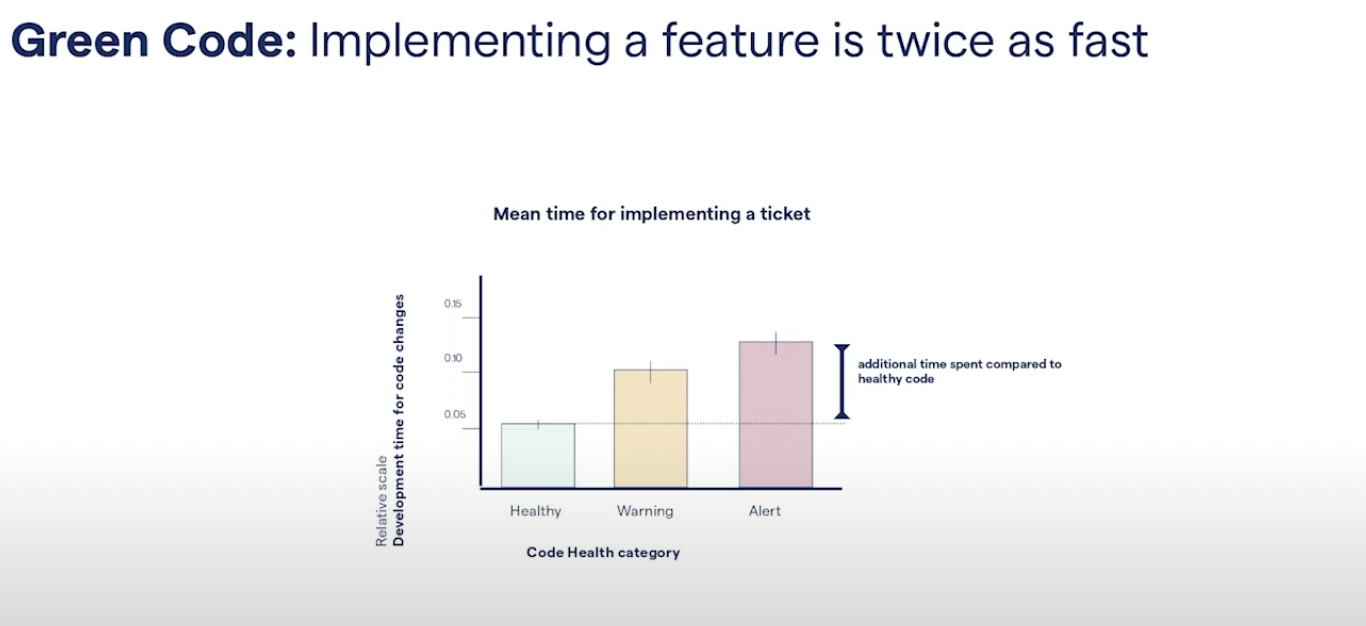
But I have to admit that this result didn’t really surprise me, because this was pretty much what I would have expected, given my years in software but what did surprise me was the next research question that we looked into.
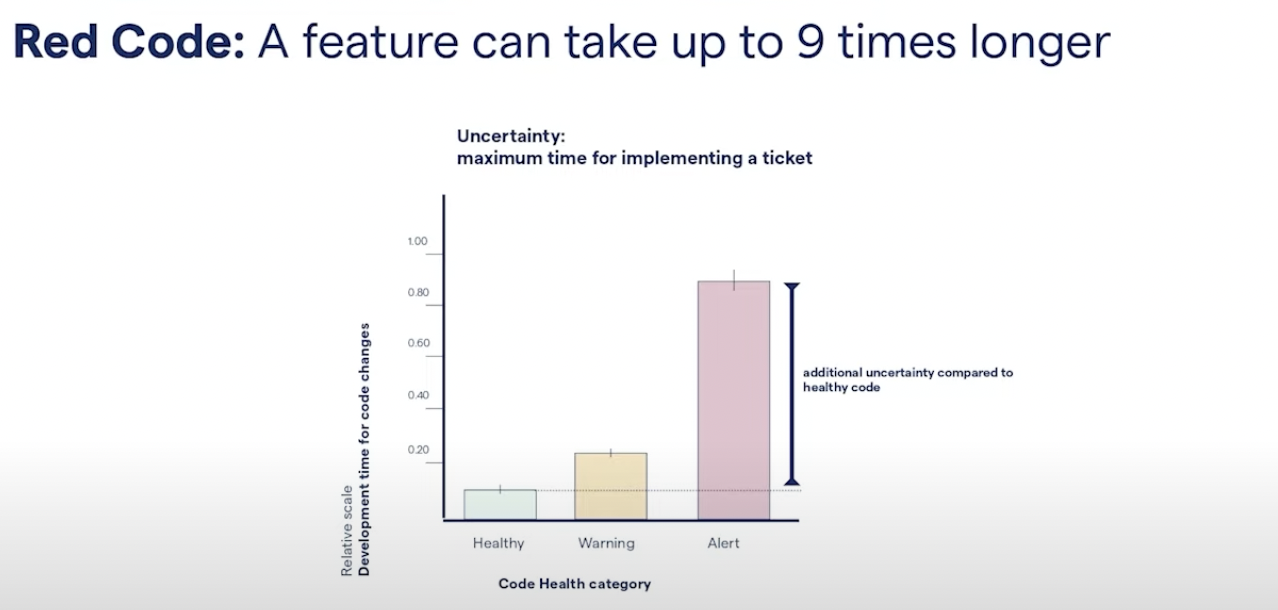
We wanted to look into something that we call the uncertainty completion time for different features and what we did differently here, is that instead of calculating the average time spent in development, we looked at the maximum time and development for every single file. What these results show is that green code seems to be very predictable, in the sense that the maximum time it takes to implement a feature is very close to the meantime, meaning there is low variability in green code. I will know roughly how long it takes to make a change to the green code. For red code, that relationship is no longer true, because in red code the maximum time it can take you to implement a feature can be an order of magnitude larger. In terms of business, this means uncertainty. I’m currently working as a CTO and I have to admit that as a CTO I strongly dislike uncertainty because it makes me look bad. For example, let’s say that I promise you that we’re going to have this new feature in a month but our code is red so it actually takes nine months to implement that feature. You are not going to be pleased.
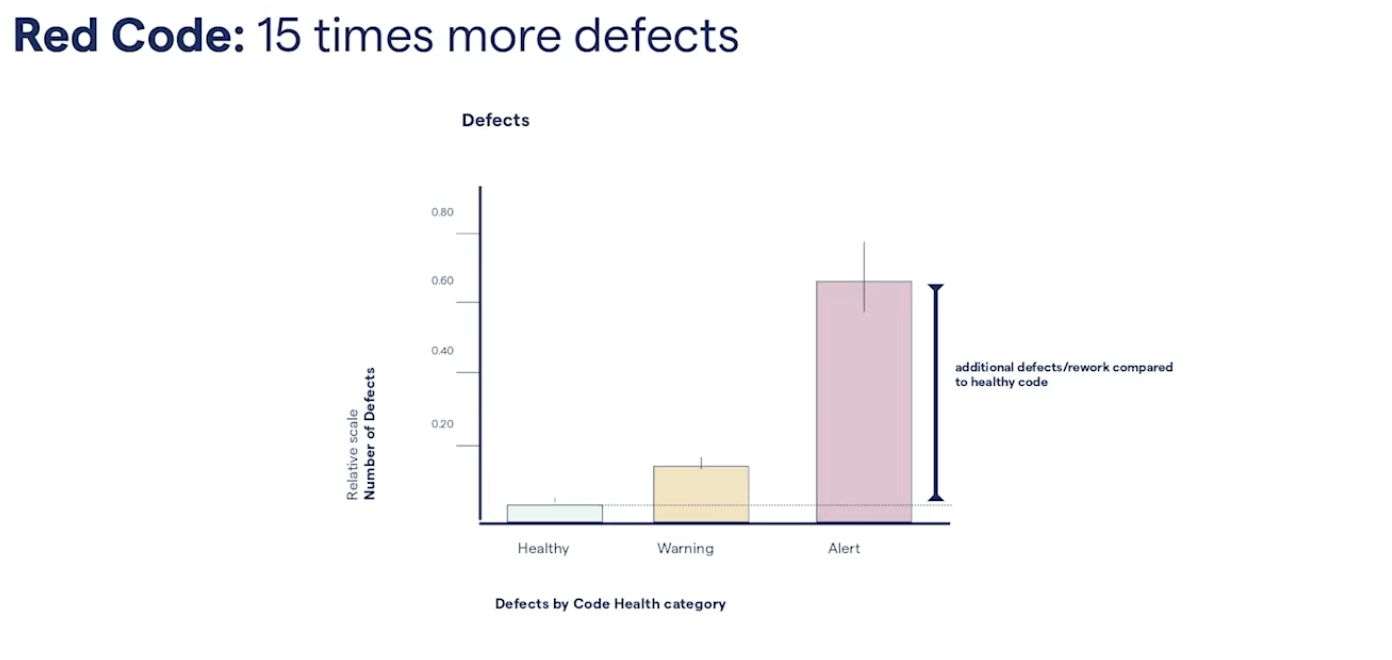
In the last data set, we also looked at the correctness perspective. We looked at the distribution of bugs or defects across code of various qualities and what we see here is that the red code has on average, 15 times more defects than the green code. This is important because this pretty much comes down to customer satisfaction and the product maturity experience.
It is easy to see how all this data relates to the business side of software, and how it’s important to a business or technical manager but is it important to us as developers? After all, you could say that if a business chooses to waste 42% of its time on technical debt, then maybe that’s a good thing for us because it means that we will be even more in demand. That’s job security at its finest. We can even get higher salaries. No, trust me on this one, technical depth is not good for you.
There’s one study in particular that looked at the happiness of developers. And yes, it is actually possible to measure that. There’s a standardized scale within psychology that you can use and you can get some very accurate numbers. They studied 1300 developers and more specifically, they looked at what makes a developer unhappy and an unhappy developer is also a developer that has lower productivity, so this is important both for well-being as well as the financial aspect.
There were three things that stood out in particular:
The first was that developers dislike it when they get stuck in problem-solving. Like when you have a bug and you think that you can fix it in five minutes, then you dive into the code and you start to fix it and something else breaks and you try to fix that and something else breaks and you end up spending two weeks trying to fix that bug. That’s extremely frustrating, and that’s where we’re likely to be with red code because remember, red code had that extreme unpredictability
The second is time pressure, because if we think something takes one week and it ends up taking nine weeks then of course the whole organization is going to get under time pressure
The third is that developers suffer tremendously when they encounter bad code that could have been avoided in the first place and that’s kind of the textbook definition of technical depth.
Given all this data that we have seen on the costs of code quality and the business impact, how do we use it and how do we integrate it into our daily work? There are a number of things I have seen that work really well. One of them is that, if we know the code quality of every single piece of code that we have, then we can also make sure that all stakeholders, not only we, developers, but also our managers and the product owners have a shared understanding. Because once everyone has a shared understanding then it becomes possible to fight decision-making biases like hyperbolic discounting. We can actually build a business case for larger improvements and logical refactorings. If we were to work with a certain part of the code, and it is red, it means a lot of uncertainty, the development would take longer, and there will be a higher risk for bugs but if we refactor it to become green, we know that we’re very likely to be at least twice as quick the next time we need to implement a feature there. So it’s one way for us to let the business people peek into our otherwise inaccessible world of code and code quality.
For more case studies and explanations, be sure to watch Adam’s presentation, on our YouTube Channel.
